





On May 21st, Philadelphia won’t just be voting for Mayor, City Council, and a few “row offices.” We will also choose nine judges: two for the Superior Court, one for Municipal Court, and six for the Court of Common Pleas. (Really, this is just the primary. But the Common Pleas and Municipal nominees will almost certainly win in November).
I’ve spent time before looking at the Court of Common Pleas. The court is responsible for the city’s major civil and criminal trials. Its judges are elected to 10-year terms. And we elect them by drawing out of a coffee can.

The result is that Philadelphia often elects judges who are unfit for the office. In 2015, Scott Diclaudio won; months later he would be censured for misconduct and negligence, and then get caught having given illegal donations in the DA Seth Williams probe. He was in the first position on the ballot. Lyris Younge was at the bottom of the first column that year and won. He has since been removed from Family Court for violating family rights and made headlines by evicting a full building of residents with less than a week’s notice.
I’ve looked before at the effect of ballot position on the Court’s elections: being in the first column nearly triples your votes. Today, I’ll use that model to simulate who will win in the upcoming race.
It’s easy to predict the Common Pleas election
Predicting elections is hard, especially without surveys. When I tried it for November’s state house election, I could only make imprecise predictions, and even then had mixed results. Why would this time be any different?
The key is that voters know nothing about the race. In May, voters are selecting six Common Pleas judges from among 25 candidates. The median voter will know the name of exactly zero of them before they enter the booth.

This lack of knowledge means that structural components end up mattering a lot. What column your name is listed in, whether you’re endorsed in the Inquirer, or how many polling places your name is handed out on a piece of paper outside of, all dictate who will win. We can observe or guess each of those, and come up with pretty accurate predictions.
When I did this exercise two years ago, I got the number of winners from the first column, and the number endorsed by the DCC, exactly right(yes, it’s that easy).
Electing qualified judges
These races matter. Philadelphia regularly elects judges who should not be judges, granting them the authority over a courtroom that decides the city’s most important cases.
As a measure of judicial quality, I use the recommendations from the Judicial Commission of the Philadelphia Bar Association. The commission evaluates candidates by an interview, a questionnaire, and interviews with people who work with them. It then rates candidates as Recommended or Not Recommended. Usually, it recommends about 2/3 of the candidates–many more than can win–and is useful as a lower-bar measure of candidate quality. My understanding is that when a candidate isn’t recommended, there’s a significant reason, though the Commission’s exact findings are kept confidential.
The court is responsible for the city’s major civil and criminal trials. Its judges are elected to 10-year terms. And we elect them by drawing out of a coffee can.
The ratings are so useful that in 2015 the Inquirer stopped endorsing judicial candidates on its own, and began printing the Commission’s recommendations (this also makes the ratings much more important for candidates).
Recently, the Commission introduced a Highly Recommended category. Unfortunately, it’s too early to know how effective it’s been. In 2015 there were three Highly Recommended candidates, and all three won. But they didn’t do statistically significantly better than the plain old Recommended Candidates in terms of votes (albeit with just three observations). In 2017, there were no Highly Recommended candidates.
This time around, there are four Highly Recommended candidates: James Crulish, Anthony Kyriakakis, Chris Hall, and Tiffany Palmer (a fifth, Michelle Hangley, dropped out because of her unlucky ballot position). None of those four are in the first column, so this year could prove a useful measure of the Bar’s impact.
In 2015, Scott Diclaudio won; months later he would be censured for misconduct and negligence, and then get caught having given illegal donations in the DA Seth Williams probe. He was in the first position on the ballot.
One note: candidates that do not submit questionnaires are not rated Recommended. Rather than reward the perverse incentive for candidates to not submit, I will consider candidates who have not yet submitted paperwork as Not Recommended.
Where will ballot position matter most?
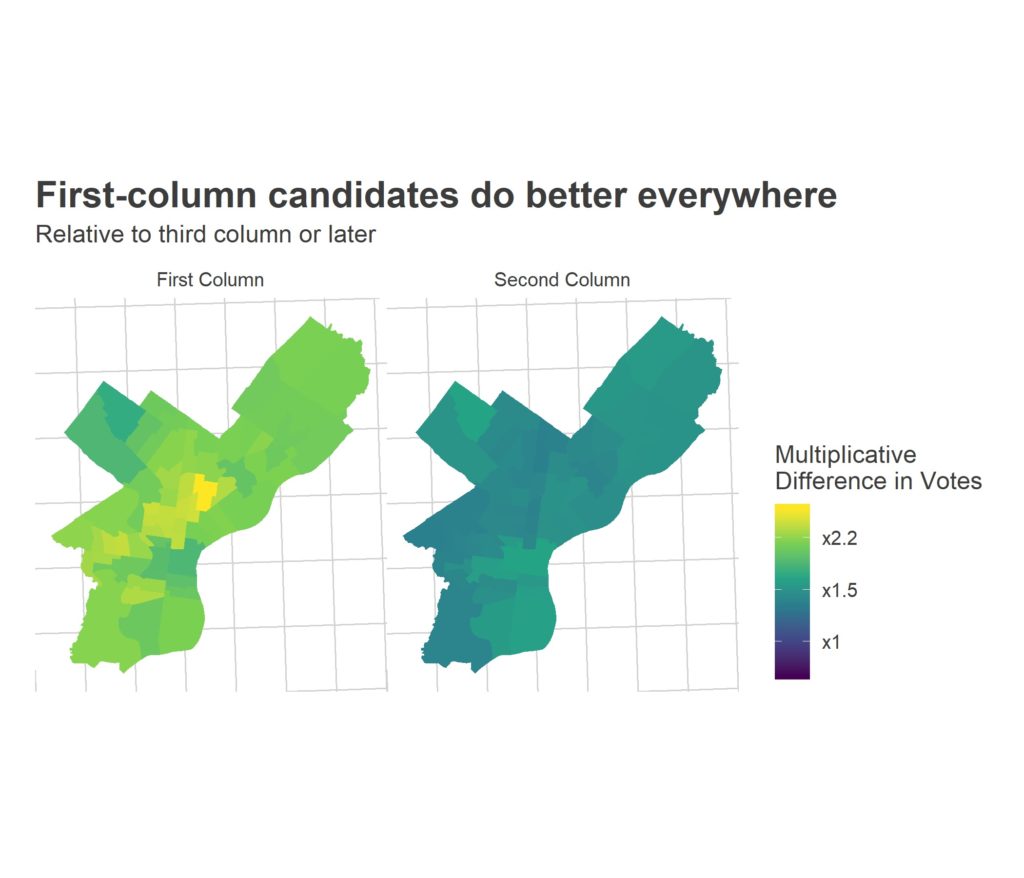
When I analysed the determinants of Common Pleas voting, being in the first column nearly tripled a candidate’s votes. Endorsements from the Democratic City Committee (DCC) and the Inquirer doubled the votes (though the causal direction here is more dubious). Remember that the Inquirer has recently just adopted the Bar’s recommendations, so the importance of the Inquirer will be transferred to the Philadelphia Bar.
The ballot this year is wide. There are just four rows and seven columns. With 25 candidates vying for six spots, a number of later column candidates will almost certainly win. See it here.
Two years ago when I simulated the race, I did so at the city-level, ignoring neighborhood patterns. But we might see vastly disproportionate turnout in some neighborhoods, and it happens that those are the neighborhoods where recommended candidates do best. So let’s be more careful. First, how much does each determinant of candidates’ votes vary by neighborhood?
Recommended candidates receive about 1.8 times as many votes on average, drawing almost all of that advantage from Center City and Chestnut Hill & Mount Airy. While overall we didn’t see a benefit to being Highly Recommended, in the neighborhood drill-down, we do see tentative evidence that those candidates did even better in the wealthier wards (a highly recommended candidate would receive the sum of the Recommended + Highly Recommended effects below).
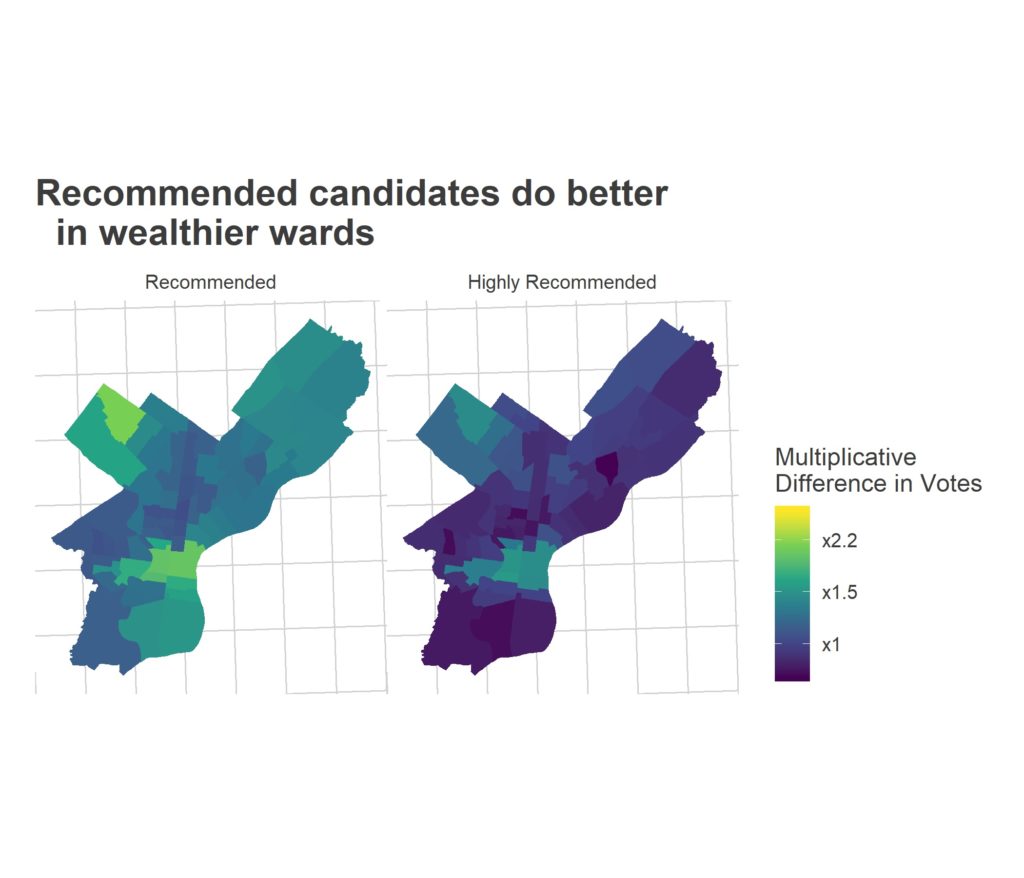 What’s going on in the other wards? The Democratic Party is especially important, especially in the traditionally-strong Black wards. (Note, I can’t identify here if that’s because they strongly adopt the party’s endorsement, or if the party endorses the candidates who would already do well). Interestingly, the party wasn’t so important in the Hispanic wards of North Philly or the Northeast.
What’s going on in the other wards? The Democratic Party is especially important, especially in the traditionally-strong Black wards. (Note, I can’t identify here if that’s because they strongly adopt the party’s endorsement, or if the party endorses the candidates who would already do well). Interestingly, the party wasn’t so important in the Hispanic wards of North Philly or the Northeast.
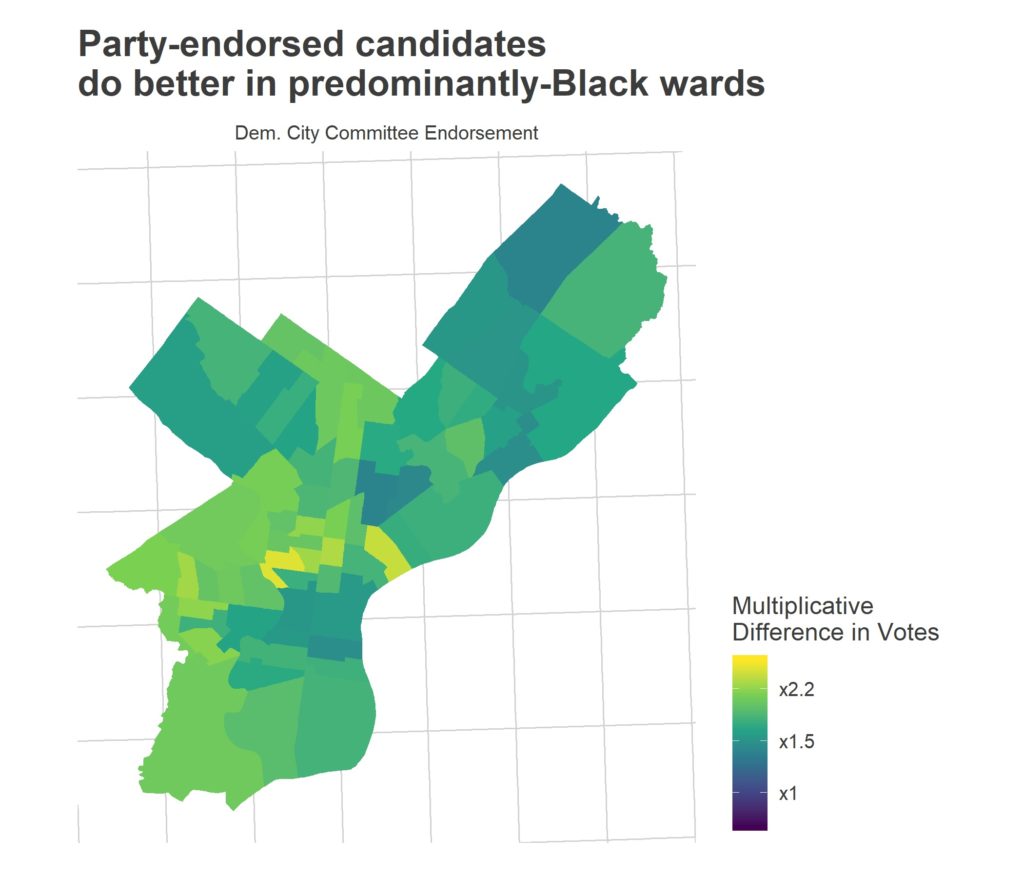
Unfortunately, all of these effects are swamped by ballot position. Candidates in the first column receive twice as many votes in every single type of ward, but especially many in lower-income wards.
Simulating the election
The task of predicting the election comes down to using these correlations, and then randomly sampling uncertainty of the correct size.
I use each candidate’s ballot position and endorsements to come up with a baseline estimate of how they’ll do in each ward. There is a lot of uncertainty for a given candidate, so I add random noise to each candidate (candidate-level effects that aren’t explained by my model have a standard deviation of about +/- 30 percent of their votes.)
I scale up the ward performance by my turnout projection. I’m using my high-turnout projections, which assume that the post-2016 surge continues in Center City and its ring, and will in general help recommended candidates, who do better in those wealthier wards.
Under the hood, the model has an estimate for each candidate. But I’m not totally comfortable with blasting those out (and what feedback loops that might cause), so let’s look at the high-level predictions instead.
The model is really optimistic about how many Recommended candidates win, mostly because there’s only one Not Recommended candidate in the first two columns. In 66 percent of simulations all six winners are Recommended, and in 33 percent all but one are (Jon Marshall at the bottom of the first column is usually the lone Not Recommended winner).
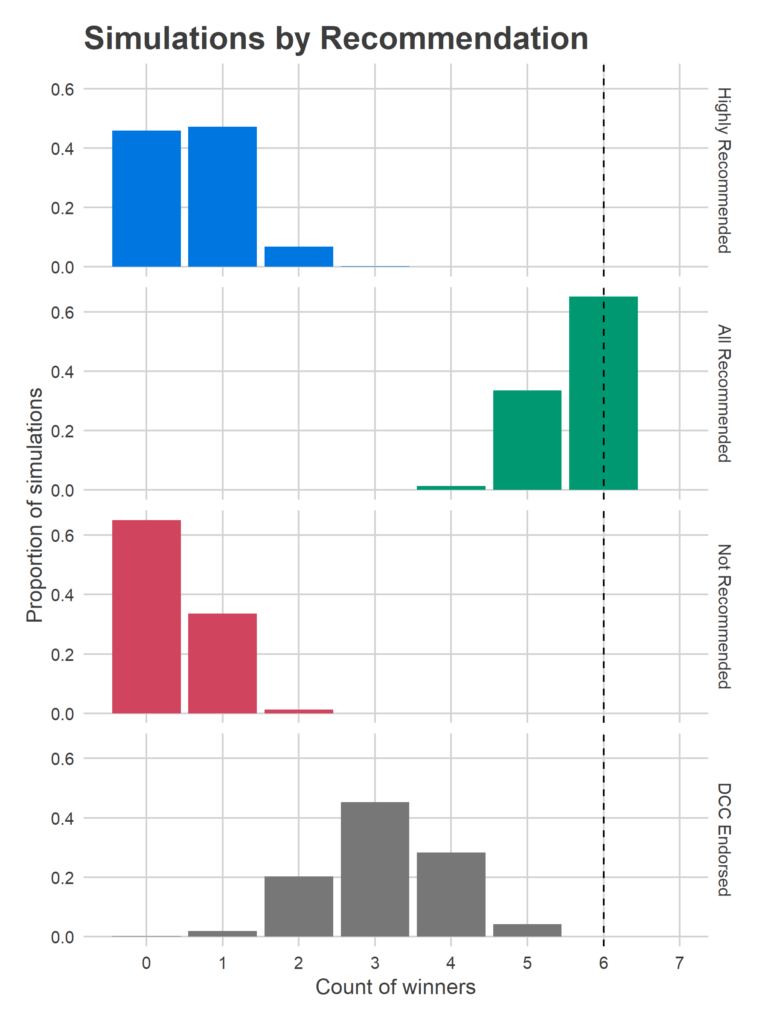
Highly Recommended candidates do less well; we get no Highly Recommended winners in 46 percent of simulations, and only one in another 47 percent. Remember that the model doesn’t think that being Highly Recommended helps more than just regular Recommended, and this year’s candidates have bad ballot position. Their performance this year will be a barometer for the power of the Bar’s endorsements; getting two winners (let alone three or four) would be a huge achievement (and presumably good for the citizens of Philadelphia, too).
DCC endorsees win an average of 3.1 of the six seats.
Of course, the true determinant is the first column.
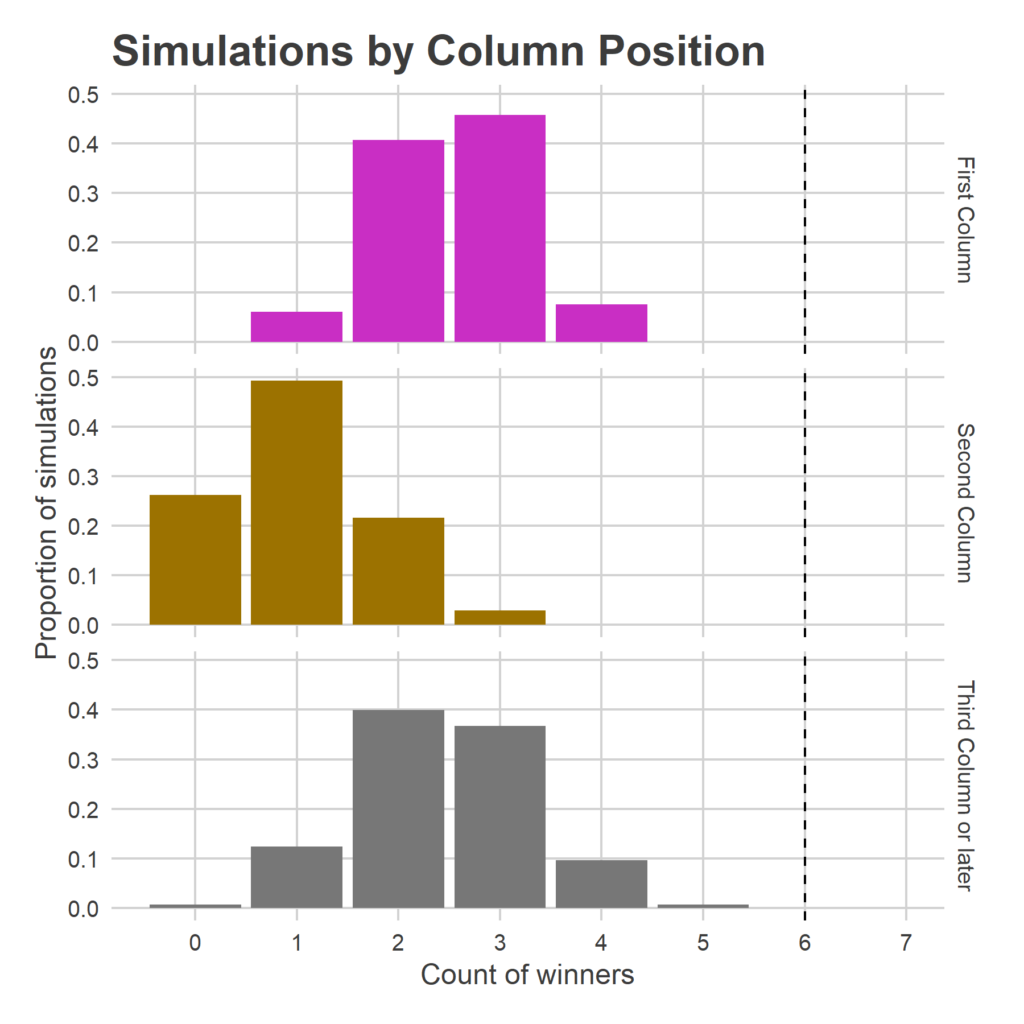
The first column produces 2.5 winners on average; the most likely outcome is three of the first-column candidates winning (45 percent of simulations), the second most likely is two (40 percent). The second column still produces 1.0 winner on average, with the remaining 2.4 winners coming from the final five columns.
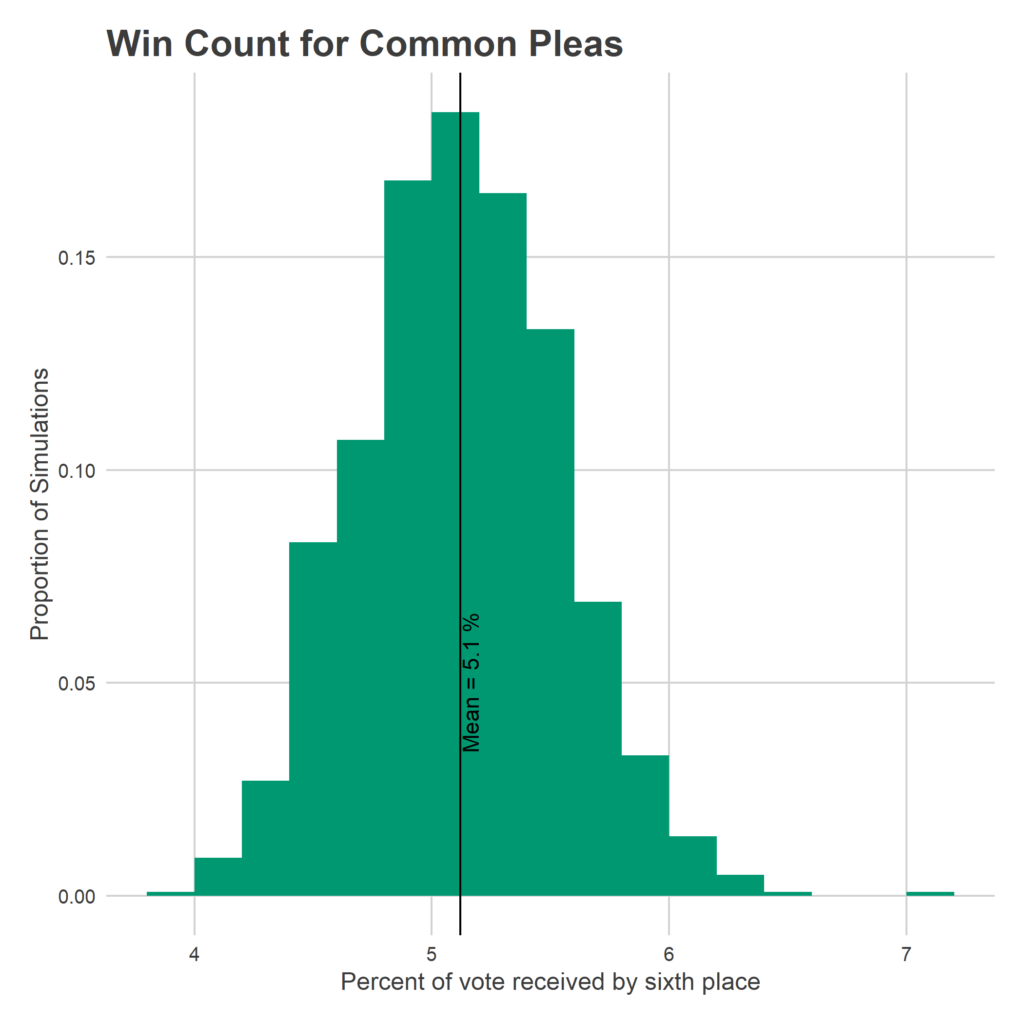
How many votes will it take to win? The average sixth-place winner wins 5.1 percent of the vote (remember that candidates can vote for multiple candidates). Assuming that 218,000 people vote, and an average of 4.5 candidates selected per voter, that comes out to 50,000 votes.
This year may be…not too bad?
In 2015, three Not Recommended candidates became ten year judges. In 2017, three more did. This year, probably at worst only one will. Why? Mostly luck; all six of those unqualified winners were in the first column, and this year seven of the eight candidates in the first two columns are Recommended.
Instead, the open question is just how qualified our judges will be. Will we stay on par with the past, which would see my model’s predicted zero or only one Highly Recommended candidate win? Or will the Bar’s Highly Recommended ratings assert themselves, and prove a bigger player this year?
Jonathan Tannen is an urban demographer who operates the blog sixty-six wards, where this analysis originally appeared.
Photo by Staff Sgt. Nicholas Rau/Released