






Last summer, the researchers at Penn Medicine’s Greene Lab, which uses public data to analyze biological questions about human genetics, had an idea. What if they could put all the genetic information about cancerous tumors into a searchable program that would allow cancer researchers to quickly gauge how a particular genetic mutation would react to a particular drug?
It would help researchers uncover the role different mutations play in cancer and even help identify additional patients who may respond to a targeted therapy.
Be Part of the Solution
Become a Citizen member.To create the program, Casey Greene, an assistant professor at Penn Med, could have hired an experienced data scientist and programmer, maybe seeking a grant to help pay for it. Instead, the Lab turned to someone else: The city’s tech community.
Over the course of 15 months, starting last summer, volunteer technologists from DataPhilly and Code for Philly met twice a month at co-working space Industrious to tackle Greene’s project. This month, they launched Cognoma——a portmanteau of “cognition” and “carcinoma”—on a publicly-accessible web platform, where it will be maintained by the Greene Lab through a partnership with Alex’s Lemonade Stand.

It was a huge community undertaking that proved another theory, of Daniel Himmelstein, a postdoctoral fellow in Greene’s lab: Science can be done in public, and with the general public.
“In addition to scientific goals, we had community goals,” Himmelstein says. “How could we get a bunch of people who hadn’t done biology or much data science working together for a philanthropic end? It’s a different model for research to do it in a collaborative way that engages the local community.”
The work on Cognoma came out of DataPhilly meetups, in which coders and others gather for networking and programming events. Amber Wanner, founder and CEO of CandiDate, a tech recruiting firm, says at some meetups she helped organize in the spring of 2016, participants started wondering how they could harness their skills for good—like the data version of Code for Philly’s civic hackathons. “We wanted to use all this talent to do something that would help the community,” says Wanner.
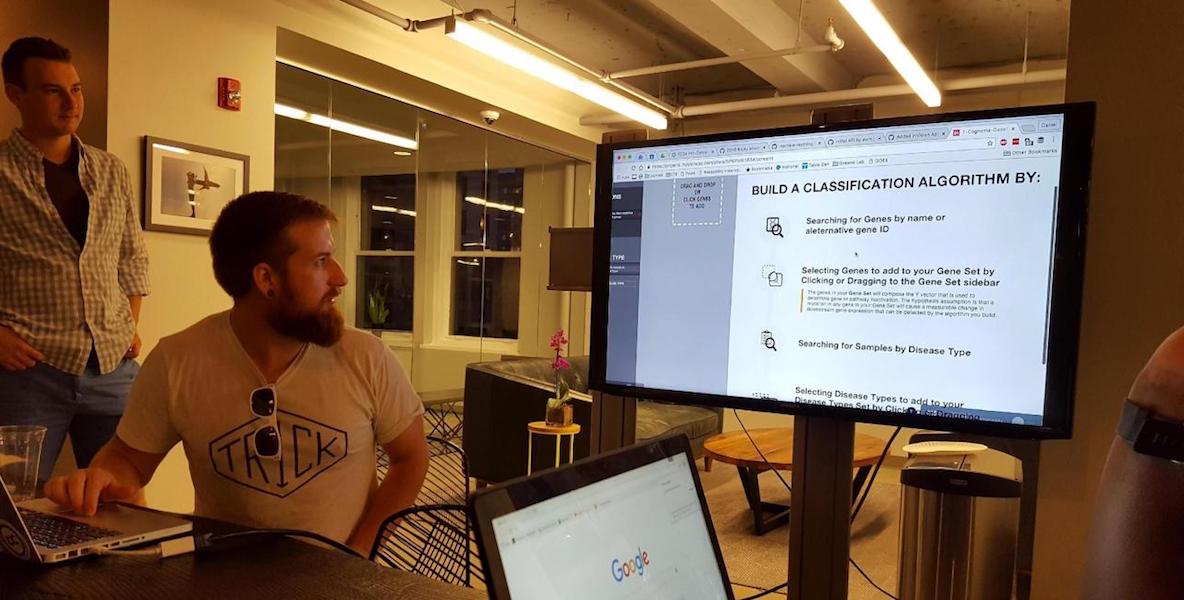
That’s when Himmelstein, who calls himself a “digital craftsman of the biodata revolution,” proposed the project that became Cognoma. He explained the premise to a meetup crowd of about 250 in a kickoff at Center City’s Milkboy in July, 2016. The Cancer Genome Atlas, produced by the National Institutes of Health, collated data on the donated tumors of about 7,300 patients, allowing researcher to study 33 types of cancer in a variety of detailed ways. One of those ways is to detect how much of each gene is present in a tumor, which themselves have about 20,000 genes each.
The Cognoma project is an extension of how Himmelstein already does science: In an open, collaborative way, on easily-accessible web sites where his research, process and results are available for anyone who wants them. That’s a direct rebuttal to the way science has long been conducted.
By studying the gene expression, and the genetic mutation that caused the cancer, researchers can develop treatments that are specifically targeted to treat the malady, what’s referred to as “precision oncology.” “Every cancer’s different and requires a different treatment,” Himmelstein says. The Cancer Genome Atlas was a huge repository of information, but as yet no one had created a simple tool for the type of analysis the Greene Lab wanted to perform. This, Himmelstein told the DataPhilly folks, was what he wanted them to do.

A couple weeks later, about 60 people showed up at Industrious to start sharing ideas about what Cognoma could do and be. “It was quite a mess in the beginning,” Himmelstein says. “Everyone has their own ideas about what to do. I had to learn how to keep people focused.” Within a few meetings, they’d figured out a process that seemed to work.
Every other Tuesday evening, from 6 to 9 p.m., between 20 and 60 people met up at Industrious. Some were experienced technologists, familiar with GitHub or with data science; others were there to learn. After pizza—donated each week by Penn, with leftovers given to the homeless—Himmelstein would start by reviewing where the project was, and what had changed since last time, often asking those who made new additions to present their work to the crowd.
Then they’d break up into four teams—cancer data; machine learning; back end; front end. Over the 15 months of the project, almost all of the original participants left; typically, they’d stay with it for two to five months before moving on. To keep track, they documented every idea, programming change and discarded direction carefully. And Himmelstein says they developed a system of tapping leaders; after contributing for some time, participants might be asked to be “maintainers,” the point person for accepting and incorporating other people’s contributions into the code.
“People would show up, and say, ‘How can I help?’” says Wanner, who hosted the events, at first with a former employee, Karin Wolok. “That’s what I heard, over and over. They would go to their jobs and then come after—because they wanted to, not because they had to. It was so inspiring and uplifting to see.”

Most of the programming happened not at the meetups, but by individuals off site, using GitHub, an Open Source development platform, which anyone can access on the web. When a participant had something to contribute, they’d run the idea by the maintainer; once they got the okay, they could write the code in GitHub and review it with the group later. In this way, each of the teams slowly developed first the framework, then the actual application, piece by piece.
Those pieces all came together last summer, when Derek Goss, now a Harriton High School senior, interned at the lab and starting bridging the code within and among the disparate groups. That allowed the programmers to see what worked, and where there were still holes. Gross’s efforts were the final push needed to create an actual product that now lives on the web at cognoma.org.
At the same time as Cognoma was slowly coming to fruition, Jay Scott of Alex’s Lemonade Stand Foundation (ALSF) decided to start a childhood cancer data lab, to help researchers analyze their work. He came to one of the events last spring, and soon after, Greene Lab won a contract with ALSF to run the nonprofit’s data lab. Cognoma is one of the programs it will use; ALSF will pay for it to reside on Amazon Web Services, and for maintenance and updating as needed.
This month, the group launched Cognoma——a portmanteau of “cognition” and “carcinoma”—on a publicly-accessible web platform, where it will be maintained by the Greene Lab through a partnership with Alex’s Lemonade Stand.
Since it launched earlier this month, Himmelstein says some 500 people have tooled around on the site, and close to 90 have made requests for analysis. To use it, they select a type of cancer, and a type of gene, and the program will email them results of the analysis within five or 10 minutes. The program is free, and no registration is required. More than that, the programming is still open and available on GitHub for anyone who wants to adapt it—to fashion it to analyze other sorts of genetic information, or for uses that even Himmelstein can’t predict.
That is partly the point. To Himmelstein, who was nominated as Scientist of the Year in the 2016 Philly Geek Awards, the Cognoma project is an extension of how he already does science: In an open, collaborative way, on easily-accessible web sites where his research, process and results are available for anyone who wants them. That’s a direct rebuttal to the way science has long been conducted—in secret, so researchers can publish their results first and secure funding. But as federal funding for research continues to diminish, those traditional mechanisms are falling short. It is not only inefficient for scientists to work in silos; it is, arguably, unethical.
Young researchers like Himmelstein are starting to change the way science is conducted. This experiment in crowd-sourced development is just one example of how he sees the future of research.
“I’m a big proponent of more Open Science,” Himmelstein says. “This is publicly-funded research, for the public good. But the public is not being engaged in science—there’s a disconnect between what researchers do and what the public hears about. This brought the general public into the process of science. Everyone can be their own scientist.”